Morig: Motion-Aware Rigging of Character Meshes from Point Clouds
SIGGRAPH ASIA 2022
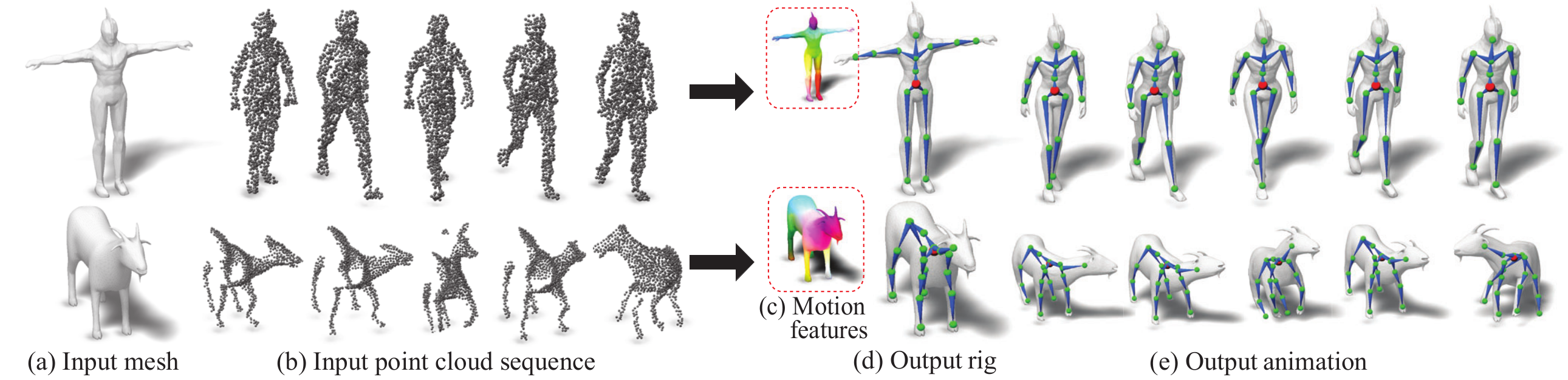
Given (a) an input mesh and (b) a single-view point cloud sequence capturing a performing character, our deep learning method, called MoRig, automatically rigs and animates the mesh based on the point cloud motion. This is achieved by (c) producing motion-aware features on the mesh encoding articulated parts from the captured motion, (d) using the features to infer an appropriate skeletal rig for the mesh, and (e) re-targeting the motion from the point cloud to the rig.
Abstract
We present MoRig, a method that automatically rigs character meshes driven by single-view point cloud streams capturing the motion of performing characters. Our method is also able to animate the 3D meshes according to the captured point cloud motion.MoRig's neural network encodes motion cues from the point clouds into features that are informative about the articulated parts of the performing character. These motion-aware features guide the inference of an appropriate skeletal rig for the input mesh, which is then animated based on the point cloud motion. Our method can rig and animate diverse characters, including humanoids, quadrupeds, and toys with varying articulation. It accounts for occluded regions in the point clouds and mismatches in the part proportions between the input mesh and captured character. Compared to other rigging approaches that ignore motion cues, MoRig produces more accurate rigs, well-suited for re-targeting motion from captured characters.
Paper
Source Code & Data
![]()
Supplementary Video
Presentation for SIGGRAPH AISA 2022
Results

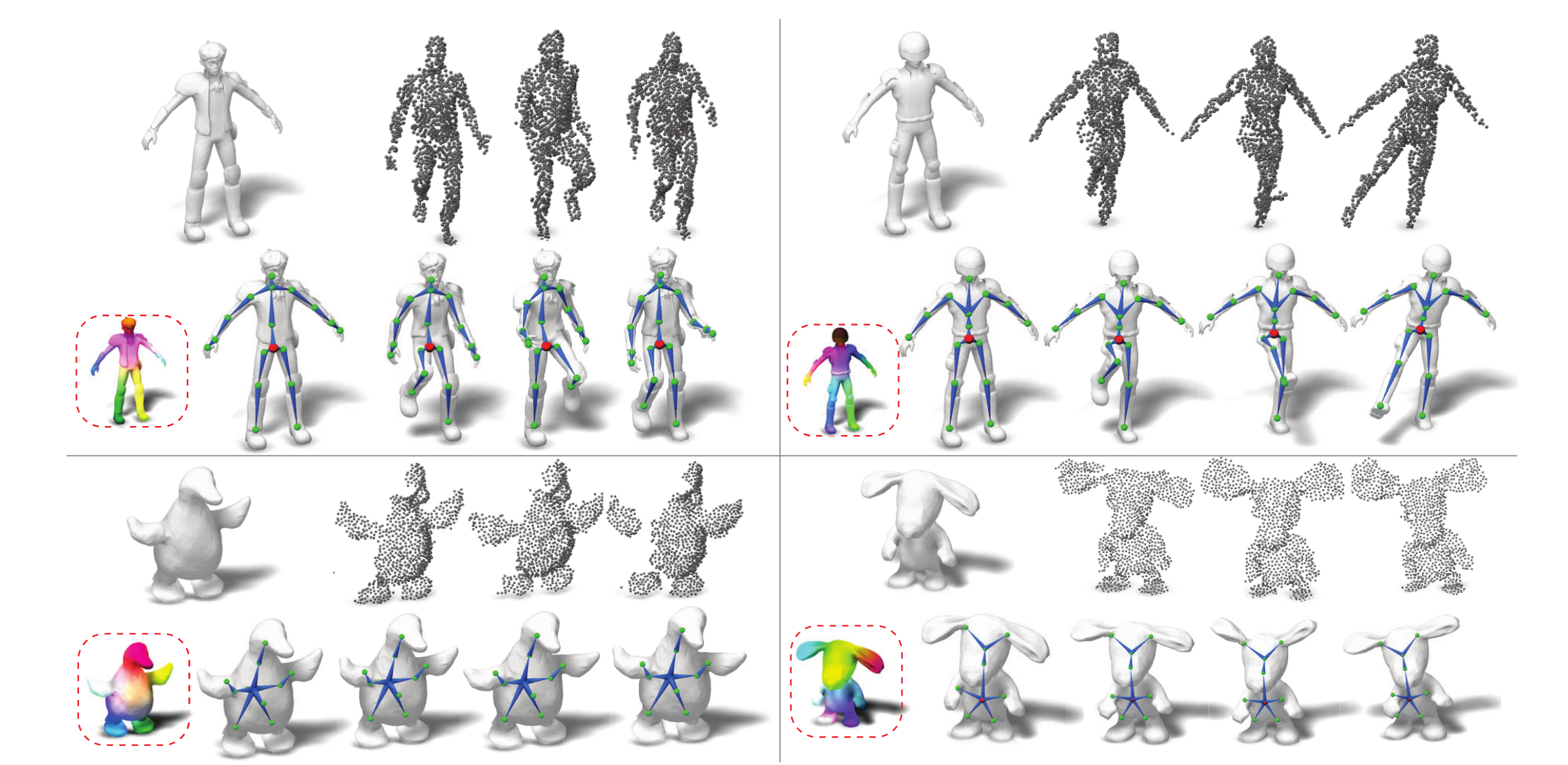
Rigging and deformation results with synthetic point cloud sequences from the ModelsResource dataset. For each example, the top row shows the original target mesh, and three of the input point cloud frames. In the bottom row, we show the predicted motion-aware features in the red rectangle, our rigging results, and also deformed meshes corresponding to the point cloud frames.
Rigging and deformation results with real-world point cloud sequences from DFaust (top) and KillingFusion (bottom). For each example, the top row shows the original target mesh, and three of the input point cloud frames. In the bottom row, we show the predicted motion features in the red rectangle, our rigging results, and then deformed meshes corresponding to the point cloud frames.
Citation
@inproceedings{xu2022morig,
title={MoRig: Motion-Aware Rigging of Character Meshes from Point Clouds},
author={Xu, Zhan and and Zhou, Yang and Yi, Li and Kalogerakis, Evangelos},
booktitle={Proc. ACM SIGGRAPH AISA},
year={2022}
}